Here is an example based on a photo I found on the net with a few faces in it (it's from here - i only found this using an image search, that page is just where i found it but I haven't otherwise read it). The yellow box is their result, the white boxes are mine (i'm not quite centring/scaling it properly yet).

The only tuning is a threshold and the grouping limit.
I'm actually quite surprised some of those faces are even found because this is one of the first tests i've done on more than a couple of images - and it has trouble with Lenna for example (but i suspect that is some aliasing issues with downsampling the larger countenance). I originally started with the eye set (from the OpenCV eye cascade), but was having trouble with false positives - e.g. eyebrows, mouth, dark spots. It seems to work much better with the face data. But most eye detectors on their own seem a bit noisy anyway so perhaps I was expecting too much.
I gave up on the cascade idea and this simply tests every position using the LBP u2 8,1 code (only 59 values) against a binary lookup table, and then each position votes on the outcome - once I get enough positive votes, it's considered a hit. This is similar to the LBP feature test in the OpenCV LBP detector, except that one uses the full 8 bits of LBP code, and of course the code is calculated on regions, not pixels.
I am only using the face and non-face images from the CBCL face dataset available here, which isn't a particularly good quality set of images. The only pre-processing i'm doing is mirroring the faces to double the training set. Training is very fast - after the images are loaded and converted to LBP, it's only taking 0.038s on my machine to `train' the 4858 positive and 4548 negative images (very plain single-threaded Java).
On the CPU the lookup isn't particularly fast (0.4s for the test image above) but I will look at porting it to OpenCL - it should be a very good fit for a GPU. If weighting isn't required, the feature description itself can be made very compact as it only requires 2 integers (64 bits) for each x,y location in the pattern - i.e. under 2K5b for a 17x17 test pattern (e.g. 19x19 training set, as the the LBP requires a 1 pixel border) which can easily fit in the constant cache.
There are still some tuning issues such as that a given threshold doesn't work equally well on all images, but it is still a promising result and there are still plenty of ideas to try.
Update (ok not really an update i hadn't published this yet ...) ... I coded something up in OpenCL and the performance is really very good - kernel time for the scaling (using a mip-map like thing), lbp building, and running the detector is around 2ms (same scales at the cpu example above). But this time doesn't include peak detection, thresholding and grouping. Still, this is pretty favourable compared to the VJ cascade as that does far fewer probes in it's 10ms runtime (and takes a week to train - if you can get that to work). Here i'm doing over 200 000 17x17 probes through 5 scales ...
I also played with a more statistically valid accumulation mechanism (as each test is independent): multiplication rather than addition (statistics isn't my strength by any stretch ... sigh). This leads to much more specific peaks as can be seen by the following picture, although i'm not sure if it leads to a more consistent threshold value (I think it does, and if that's true, I probably don't even need to do peak detection ...).
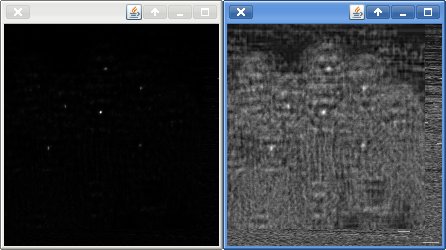
Both images are normalised.
Update 2: Had a bit more of a play this morning, tried a couple of different kernel topologies and using LDS to reduce memory bandwidth requirements. Got the kernel time of my test case down to 1.3ms, vs the 2.1ms yesterday (on a Radeon HD 7970). I also found the new combination metric is working well - I can use a specific value as the threshold and remove the peak detection stage entirely. It doesn't work too well with the eye data (way too many false positives), but it's pretty good with faces, so far.



